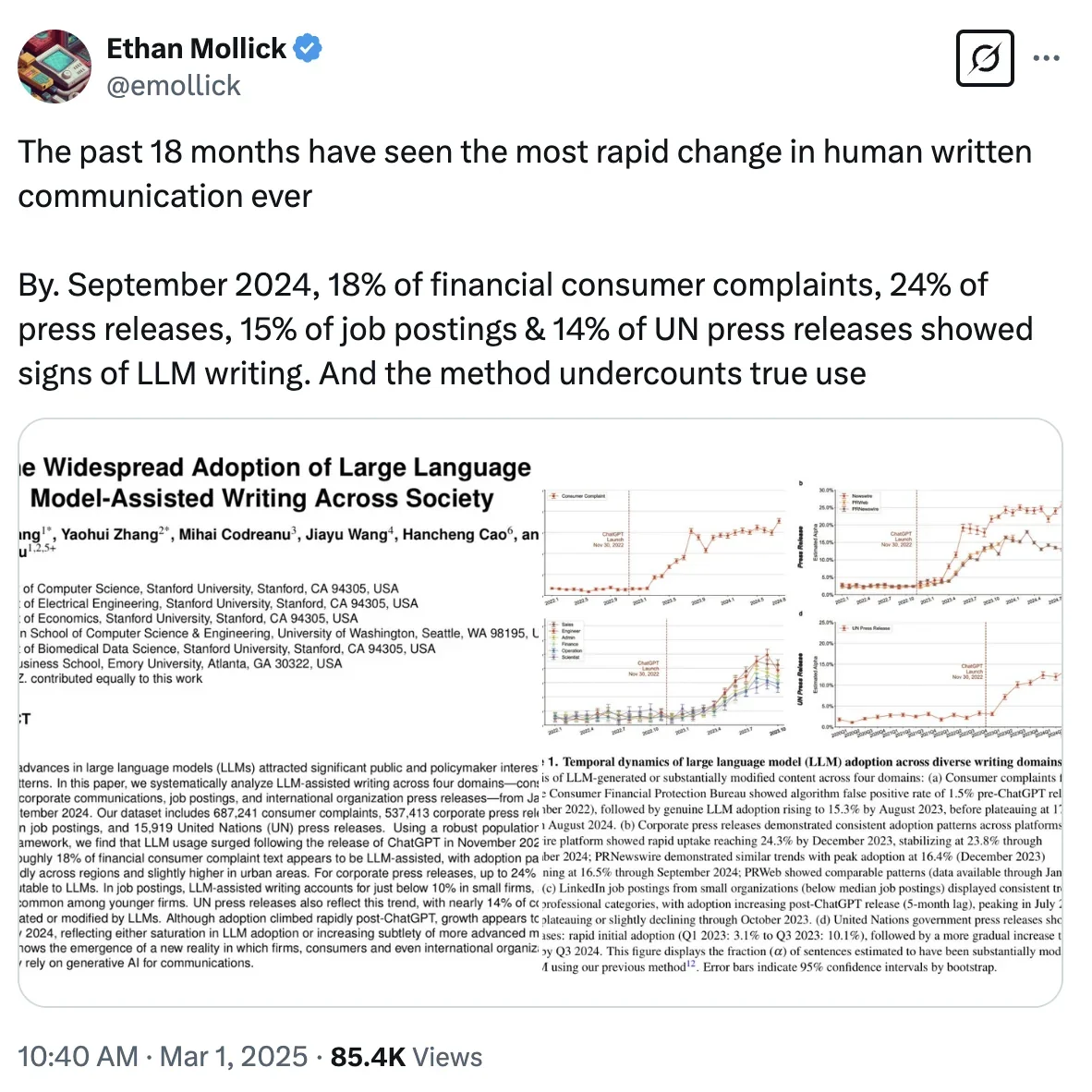
They developed their own detector described in another paper. Basically, this reverse-engineers texts based on their vocabulary to provide an estimate on how much of them were ChatGPT.
This sounds plausible to me, as specific models (or even specific families) do tend to have the same vocabulary/phrase biases and “quirks.” There are even some community “slop filters” used for sampling specific models, filled with phrases they’re known to overuse through experience, with “shivers down her spine” being a meme for Anthropic IIRC.
It’s defeatable. But the “good” thing is most LLM writing is incredibly lazy, not meticulously crafted to avoid detection.
This is yet another advantage of self hosted LLMs as they:
Tend to have different quirks than closed models.
Have finetunes with the explicit purpose of removing their slop.
Can use exotic sampling that “bans” whatever list of phrases you specify (aka the LLM backtracks and redoes it when it runs into them, which is not normally a feature you get over APIs), or penalizes repeated phrases (aka DRY sampling, again not a standard feature).


{kind=link}
They developed their own detector described in another paper. Basically, this reverse-engineers texts based on their vocabulary to provide an estimate on how much of them were ChatGPT.
This sounds plausible to me, as specific models (or even specific families) do tend to have the same vocabulary/phrase biases and “quirks.” There are even some community “slop filters” used for sampling specific models, filled with phrases they’re known to overuse through experience, with “shivers down her spine” being a meme for Anthropic IIRC.
It’s defeatable. But the “good” thing is most LLM writing is incredibly lazy, not meticulously crafted to avoid detection.
This is yet another advantage of self hosted LLMs as they:
Tend to have different quirks than closed models.
Have finetunes with the explicit purpose of removing their slop.
Can use exotic sampling that “bans” whatever list of phrases you specify (aka the LLM backtracks and redoes it when it runs into them, which is not normally a feature you get over APIs), or penalizes repeated phrases (aka DRY sampling, again not a standard feature).